개요
병합정렬 알고리즘은 배열을 하나의 원소가 될 때까지 분할하여 정렬 후 정렬된 부분 배열을 병합, 병합된 부분 배열끼리 다시 정렬 후 병합하는 과정을 반복하여 전체 배열을 정렬하는 알고리즘이다.

위의 자료와 같이 분할하고 병합하는 과정이 똑같이 반복되기 때문에 재귀함수로 구현이 가능하다.
코드
void Merge_Sort(int A[], int p, int r) {
if (p < r) {
int q = (p + r) / 2;
Merge_Sort(A, p, q); // 분할
Merge_Sort(A, q + 1, r); // 분할
Merge(A, p, q, r); // 정렬
}
}
위의 코드는 배열을 분할하고 정렬하는 함수를 재귀적으로 수행하는 Merge_Sort 함수이다.
여기서 p와 r은 정렬할 배열의 각각 첫 번째 인덱스와 마지막 인덱스를 의미한다.
즉, 분할한 배열의 크기가 1이 되어 if절을 만족하지 않으면(p == r) 자동으로 분할을 멈추고 정렬 단계에 들어간다.
q는 정렬할 배열의 중간 인덱스값이다.
void Merge(int A[], int p, int q, int r) {
int n1 = q - p + 1;
int n2 = r - q;
int L[n1 + 1];
int R[n2 + 1];
for (int i = 0; i < n1; i++) {
L[i] = A[p + i];
}
for (int j = 0; j < n2; j++) {
R[j] = A[q + j + 1];
}
L[n1] = INT_MAX;
R[n2] = INT_MAX;
int i, j = 0;
for (int k = p; k <= r; k++) {
if (L[i] <= R[j]) { // 왼쪽배열의 키 값이 오른쪽배열의 키 값보다 작거나 같은 경우
A[k] = L[i];
i += 1;
}
else { // 오른쪽배열의 키 값이 왼쪽배열의 키 값보다 작은 경우
A[k] = R[j];
j += 1;
}
}
}위 코드는 실질적인 정렬을 담당하는 Merge 함수이다.
쉽게 예를 들어 [ 3, 41, 26, 52 ] 부분배열이 어떻게 정렬되는지 살펴보자.
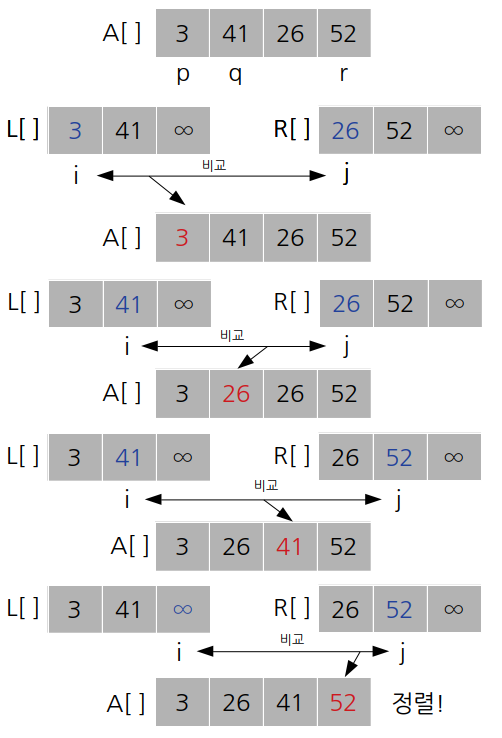
우선 [ 3, 41, 26 ,52 ] 의 부분 배열은 [ 3, 41 ] , [ 52, 26 ] 이 각각 정렬되어 병합된 배열일 것이다.
우선 [ 3, 41, 26, 52 ] 를 반으로 쪼갠 것보다 크기가 1 큰 배열을 두 개 만들어 준다.(L[ ], R[ ])
L[ ]과 R[ ]에 [ 3, 41, 26, 52 ] 의 값을 넣어주고 각각 배열의 마지막 부분에는 $ \infty $ 값을 넣어준다.
코드에는 int 자료형의 가장 큰 수인 2,147,483,647 값을 넣어주었다. (climits 헤더의 INT_MAX 매크로)
i와 j의 값을 0으로 세팅하고 L[i] 와 R[j]의 대소비교를 진행한다.
위의 예시에서는 L[i]가 더 작으므로 L[i] 값을 A[k]에 삽입하고 i의 값을 1 늘려준다.
그렇게 되면 i의 위치가 바뀐다. 바뀐 i의 위치를 적용하여 다시 L[i]와 R[j]의 대소비교를 진행한다.
이번에는 R[j]가 더 작으므로 R[j]의 값을 A[k]에 삽입하고 j의 값을 1 늘려준다.
이번에는 L[i]가 더 작다. A[k]에 L[i] 값을 삽입한다. 그런데 이제는 바뀐 i의 값에 해당하는 원소가 $ \infty $ 이다. 이제서야 우리가 $ \infty $ 를 채용한 이유가 나온다.
$ \infty $ 는 경계값으로, 한 쪽 배열의 원소가 모두 본 배열에 삽입되었을 때 남은 한 쪽의 배열을 그대로 본 배열에 삽입하게 해주는 역할을 한다.
이후 계속 정렬을 해주면, 정렬된 부분배열 내지는 배열을 얻을 수 있다.
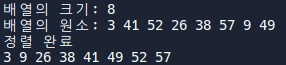
실행 결과
main 함수에 이것저것 추가해주고 코드를 돌려보면 다음과 같이 잘 작동하는 것을 볼 수 있다.


분석
- 병합 정렬을 진행할 때 진행되는 순서는 다음과 같다.

- 병합 정렬 알고리즘의 수행시간을 $ \Theta $-표기법으로 나타내면 $ \Theta(n \mathrm{lg}n) $ 이다. (여기서 lgn은 $ log_2n $ 이다.)
- 충분히 큰 입력에 대해 병합정렬이, 수행시간이 $ \Theta(n^2) $인 삽입 정렬보다 성능이 좋다.
'알고리즘 > 알고리즘' 카테고리의 다른 글
| [알고리즘][C++] 이진검색 (Binary Search) (0) | 2023.06.06 |
|---|---|
| [알고리즘][C++] 선택정렬 (Selection Sort) (0) | 2023.05.21 |
| [알고리즘][문제풀이][C++] 두 이진수 더하기 (0) | 2023.05.21 |
| [알고리즘][C++] 선형검색 (Linear Search) (0) | 2023.05.06 |
| [알고리즘][C++] 삽입정렬 (Insertion Sort) (0) | 2023.05.05 |